Ta có 1 dataset gồm 30 dòng và 6 cột, trong đó có 1 số cột bị missing value. Để kiểm tra nhanh, ta sẽ dùng lệnh summary() tuy nhiên lệnh này không kiểm tra được các cột là character.
dim(df)
[1] 30 6
df
name school student revenue expenditure type
1 RIO GRANDE CITY GRULLA ISD 15 9007 14409 12858 <NA>
2 KEENE ISD 5 1016 16272 11291 <NA>
3 BRYAN ISD 25 16005 14613 NA <NA>
4 GOODRICH ISD 3 244 18543 13730 <NA>
5 HALE CENTER ISD 3 597 15541 NA <NA>
6 LAMESA ISD 1 1602 18810 NA <NA>
7 EVOLUTION ACADEMY CHARTER SCHOOL 3 669 12607 NA I
8 MALONE ISD 1 153 17031 NA <NA>
9 RAMIREZ CSD 1 26 22447 17483 <NA>
10 ST MARY'S ACADEMY CHARTER SCHOOL 1 401 13897 13384 I
11 BLOOMINGTON ISD 5 825 13999 13182 <NA>
12 LOMETA ISD 2 317 22798 NA <NA>
13 DR M L GARZA-GONZALEZ CHARTER SCHOOL 1 166 14006 NA I
14 HARDIN-JEFFERSON ISD 5 2602 11022 NA <NA>
15 ROSCOE COLLEGIATE ISD 4 3076 29616 NA <NA>
16 WESTPHALIA ISD 1 155 14312 NA <NA>
17 HEMPHILL ISD 3 901 16550 NA <NA>
18 MOODY ISD 4 687 15586 NA <NA>
19 PEWITT CISD 3 866 13718 NA <NA>
20 CORRIGAN-CAMDEN ISD 3 817 17796 15432 <NA>
21 PATTON SPRINGS ISD 1 86 29806 25965 <NA>
22 WINNSBORO ISD 4 1532 21267 11859 <NA>
23 PAINT CREEK ISD 1 95 29940 22333 <NA>
24 LIBERTY-EYLAU ISD 4 2131 19971 12415 <NA>
25 GOOSE CREEK CISD 31 23833 14213 12111 <NA>
26 TEXAS PREPARATORY SCHOOL 2 120 16009 16096 I
27 TULOSO-MIDWAY ISD 6 3745 15313 10669 <NA>
28 NUECES CANYON CISD 2 254 16804 15142 <NA>
29 MISSION CISD 23 13838 15204 12062 <NA>
30 UNITED ISD 50 39243 12654 11226 <NA>
sapply(df, class)
name school student revenue expenditure type
"character" "numeric" "numeric" "numeric" "numeric" "character"
summary(df)
name school student revenue expenditure type
Length:30 Min. : 1.00 Min. : 26.0 Min. :11022 Min. :10669 Length:30
Class :character 1st Qu.: 1.25 1st Qu.: 246.5 1st Qu.:14238 1st Qu.:12062 Class :character
Mode :character Median : 3.00 Median : 821.0 Median :15798 Median :13182 Mode :character
Mean : 7.10 Mean : 4167.0 Mean :17492 Mean :14543
3rd Qu.: 5.00 3rd Qu.: 2484.2 3rd Qu.:18743 3rd Qu.:15432
Max. :50.00 Max. :39243.0 Max. :29940 Max. :25965
NA's :13
Do vậy để kiểm tra nhanh toàn bộ dataset df này có bao nhiêu giá trị missing value ở tất cả các cột (gồm character và numeric) thì ta dùng function md.pattern() trong package mice.
This function is useful for investigating any structure of missing observations in the data.
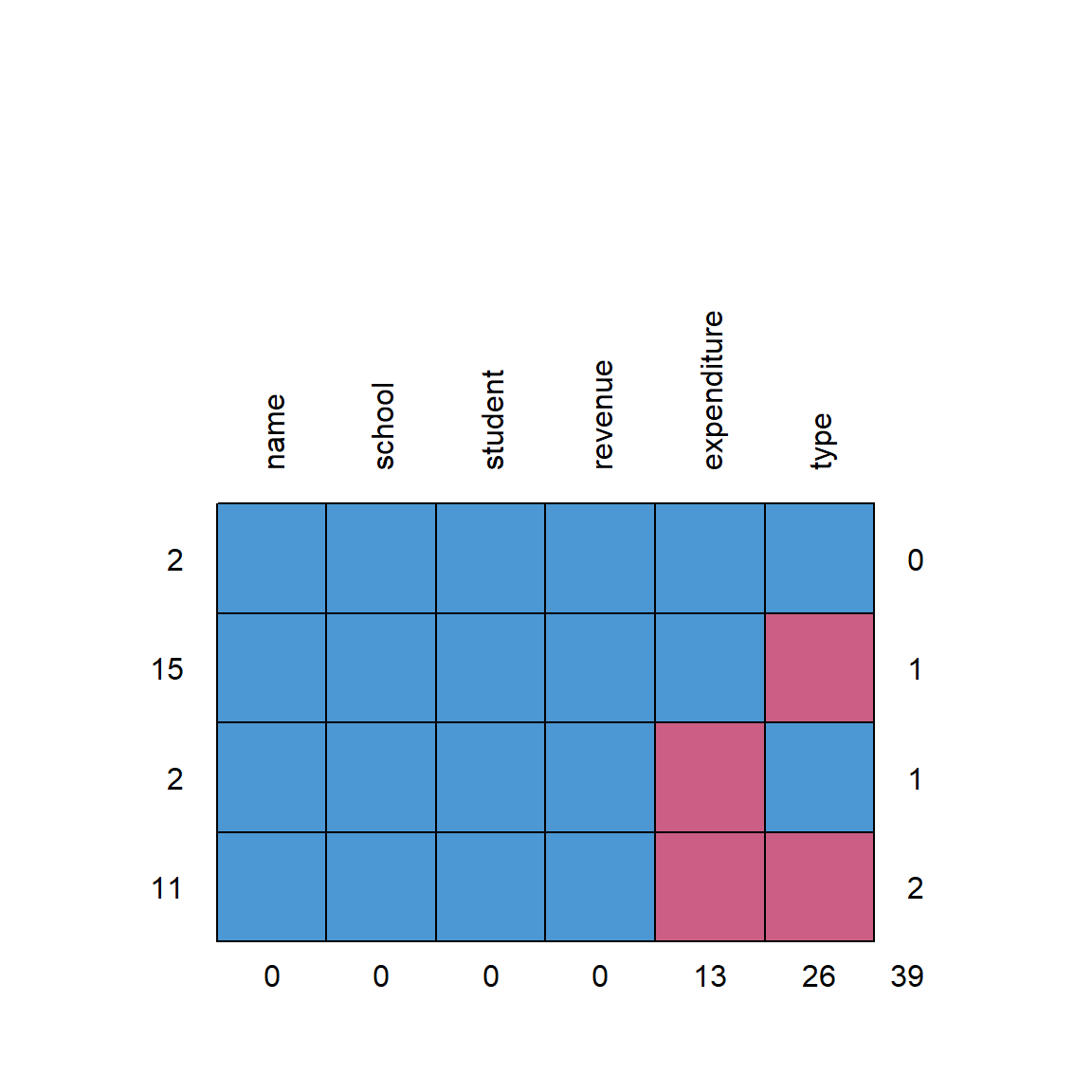
Ở đây ta phân tích kỹ các con số từ đồ thị này để đánh giá tình hình missing value trong bộ dữ liệu. Cụ thể:
Giá trị nằm ngang dưới cùng (0, 0, 0, 0, 13, 26 và 39) lần lượt là số lượng missing value trong từng cột, còn số 39 nghĩa là trong toàn bộ dataset df (gồm 30 dòng và 6 cột, tạo thành tổng cộng 180 ô dữ liệu) có 39 ô bị giá trị trống. Được tính theo công thức: \(0 + 0 + 0 + 0 + 13 + 26 = 39\).
Giá trị nằm bên trái (2, 15, 2, 11) tương ứng với các con số bên phải (0, 1, 1, 2) có ý nghĩa là:
### số 2 là dataset chỉ còn 2 dòng (hàng) dữ liệu sau khi na.omit() toàn bộ các cột### nghĩa là lúc này dataset không (số 0) còn cột nào có giá trị missing valuedf_clean_all_column <-na.omit(df)row.names(df_clean_all_column) <-NULLdim(df_clean_all_column)
[1] 2 6
df_clean_all_column
name school student revenue expenditure type
1 ST MARY'S ACADEMY CHARTER SCHOOL 1 401 13897 13384 I
2 TEXAS PREPARATORY SCHOOL 2 120 16009 16096 I
### số 15 là dataset có 15 dòng (hàng) dữ liệu đầy đủ tất cả thông tin (từ cột đầu tiên đến cột expenditure) ### ngoại trừ cột type (màu đỏ), lúc này toàn bộ giá trị ở cột type là NA.df_clean_1 <- df[complete.cases(df$name, df$school, df$student, df$revenue, df$expenditure), ]df_clean_1a <- df_clean_1[is.na(df_clean_1$type), ] row.names(df_clean_1a) <-NULLdim(df_clean_1a)
### số 2 là dataset có 2 dòng (hàng) dữ liệu đầy đủ tất cả thông tin (từ cột đầu tiên đến cột type) ### ngoại trừ cột expenditure (màu đỏ), lúc này toàn bộ giá trị ở cột expenditure là NA.df_clean_2 <- df[complete.cases(df$name, df$school, df$student, df$revenue, df$type), ]df_clean_2a <- df_clean_2[is.na(df_clean_2$expenditure), ] row.names(df_clean_2a) <-NULLdim(df_clean_2a)
[1] 2 6
df_clean_2a
name school student revenue expenditure type
1 EVOLUTION ACADEMY CHARTER SCHOOL 3 669 12607 NA I
2 DR M L GARZA-GONZALEZ CHARTER SCHOOL 1 166 14006 NA I
### số 11 là dataset có 11 dòng (hàng) dữ liệu đầy đủ tất cả thông tin (từ cột đầu tiên đến cột revenue) ### ngoại trừ cột expenditure và type (màu đỏ), lúc này toàn bộ giá trị ở cột expenditure và type là NA.df_clean_3 <- df[complete.cases(df$name, df$school, df$student, df$revenue), ]df_clean_3a <- df_clean_3[is.na(df_clean_3$type), ] df_clean_3b <- df_clean_3a[is.na(df_clean_3a$expenditure), ] row.names(df_clean_3b) <-NULLdim(df_clean_3b)
[1] 11 6
df_clean_3b
name school student revenue expenditure type
1 BRYAN ISD 25 16005 14613 NA <NA>
2 HALE CENTER ISD 3 597 15541 NA <NA>
3 LAMESA ISD 1 1602 18810 NA <NA>
4 MALONE ISD 1 153 17031 NA <NA>
5 LOMETA ISD 2 317 22798 NA <NA>
6 HARDIN-JEFFERSON ISD 5 2602 11022 NA <NA>
7 ROSCOE COLLEGIATE ISD 4 3076 29616 NA <NA>
8 WESTPHALIA ISD 1 155 14312 NA <NA>
9 HEMPHILL ISD 3 901 16550 NA <NA>
10 MOODY ISD 4 687 15586 NA <NA>
11 PEWITT CISD 3 866 13718 NA <NA>